https://newbiecs.tistory.com/394
'google-api-python-client'를 사용한 유튜브 데이터 가져오기 - Google Cloud 및 Python 설정 가이드 (1)
안녕하세요. Prography 8기로 활동하고 있습니다. 8기에 저희 팀은 'google-api-python-client' 를 사용하여 유튜버의 영상들을 가져오고, Description 에 적혀있는 재료 정보들로 사용자가 필요한 재료 데이터
newbiecs.tistory.com
안녕하세요.
전 게시글에서는 pandas와 argparse 를 이용하여 csv 파일을 만들고, 인터페이스를 파싱했습니다.
오늘은 아래 사진에서 빨간색 네모로 강조 된 부분의 데이터들을 가져오겠습니다.
google-api-client-python 에서는 영상에 관련 된 데이터를 제공합니다.
url_pk, channel_id, title, description, thumbnails, view_count, like_count, published, play_time
오늘은 이 데이터들을 가져와서 csv 를 만드는 것 까지 완성해보겠습니다.
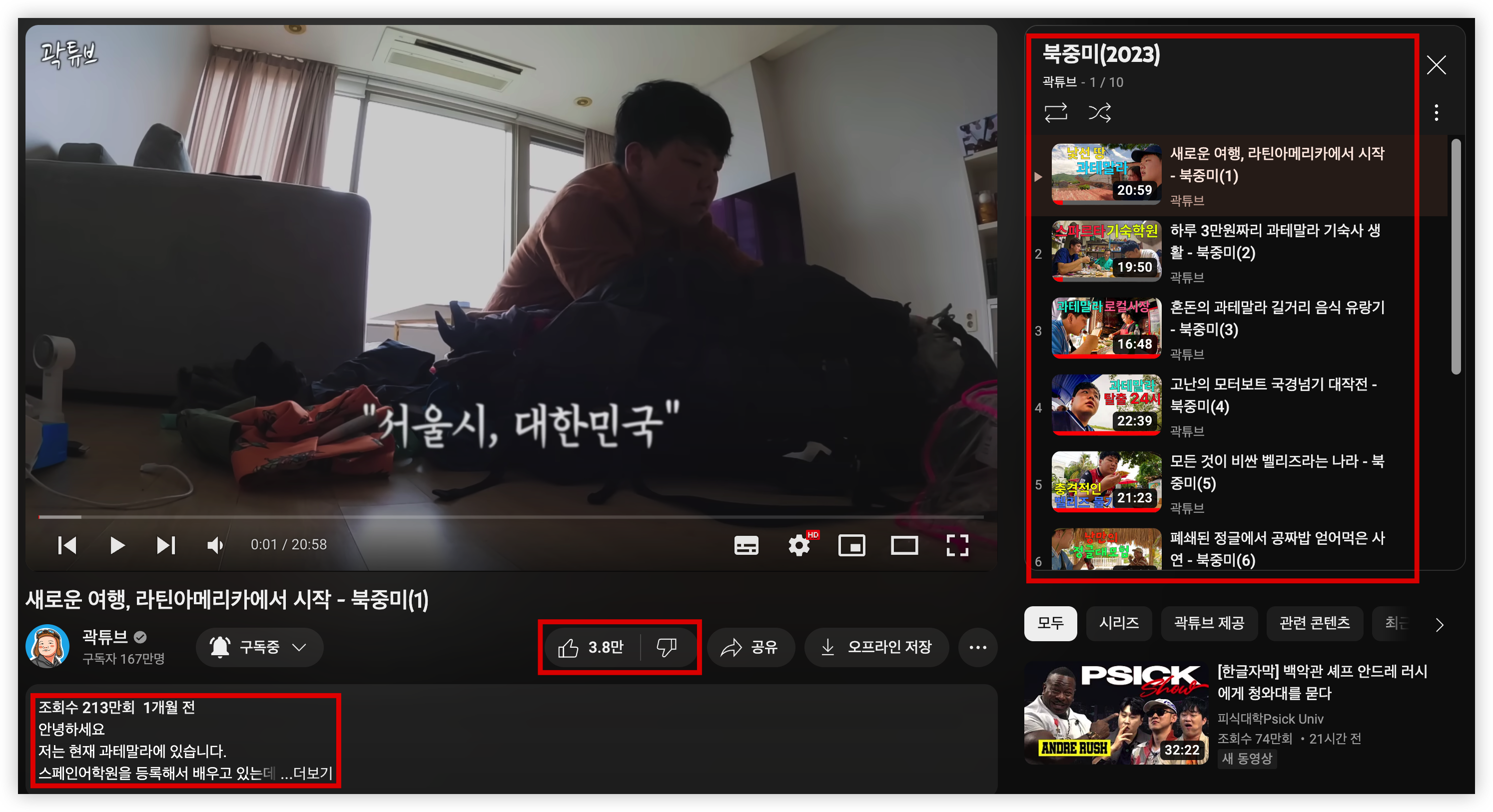
유튜브 재생목록 안에 영상들 pk 가져오기
전 게시글에서 youtuber 라는 함수명은 get_all_youtube_playlists로 변경되었습니다.
먼저 우리는 수 많은 플레이리스트 중에 어떤 플레이리스트를 가져올 지 정해야 합니다.
아래 사진에 재생목록들이 보이고, 상단에 빨간색으로 번호를 강조 했습니다.
이 순서대로 재생목록 데이터를 가져올 수 있습니다.

아래 코드는 재생목록을 선택하면 그 안에 있는 영상 데이터(video_id)를 return 합니다.
그리고 전 게시글에서는 playlist() 를 사용했습니다.
하지만 지금은 재생목록(playlist) 안에 있는 데이터들(items)의 id를 가져올 것 입니다.
또 전 게시글에서는 언급하지 않은 google-api-python-client 의 part 에 대해 알아보겠습니다.
snippet: 이 부분은 리소스의 기본 정보를 포함하고 있습니다. 예를 들어 YouTube 비디오의 경우 title, description, publishedAt과 같은 비디오의 기본 정보가 여기에 포함됩니다.
contentDetails: 이 부분은 리소스의 콘텐츠 세부 정보를 제공합니다. 예를 들어 YouTube 비디오의 경우 duration과 같은 비디오의 길이와 같은 콘텐츠에 관한 세부 정보가 여기에 포함됩니다.
statistics: 이 부분은 리소스의 통계 정보를 포함합니다. 예를 들어 YouTube 비디오의 경우 viewCount, likeCount, dislikeCount와 같은 비디오의 통계 정보가 여기에 포함됩니다.
정리하면 리소스의 기본 정보, 콘텐츠 세부 정보, 통계 정보를 제공합니다.
EX) part="snippet,contentDetails" 나는 유튜브 영상의 기본 정보와 콘텐츠 세부 정보를 가져올거야!
def get_videos_from_playlists_items(self, playlist_id: str) -> list:
"""
:param playlist_id:
:return: video_list
유튜버가 가지고 있는 재생 목록에서 보고 싶은 플레이 리스트를 선택하면 플레이 리스트 안에 있는 데이터(video_id)를 return.
"""
video_list = []
next_page = True
playlist_items = self.youtube.playlistItems().list(
part="snippet,contentDetails",
playlistId=playlist_id,
maxResults=50
)
while next_page:
response = playlist_items.execute()
data = response['items']
for video in data:
video_id = video['contentDetails']['videoId']
# * video_id 를 중복없이 video_list 에 삽입한다.
if video_id not in video_list:
video_list.append(video_id)
# Do we have more pages?
if 'nextPageToken' in response.keys(): # 다음 페이지가 있다면 'nextPageToken' = True 없다면 'nextPageToken' 삭제
next_page = True
playlist_items = self.youtube.playlistItems().list(
part="snippet,contentDetails",
playlistId=playlist_id,
pageToken=response['nextPageToken'], # * google-api-python-client 에서 지원하는 nextPageToken
maxResults=50
)
else:
next_page = False # * 'nextPageToken' in response.keys() 가 없다면 End
return video_list
video_list 에는 영상들의 pk 값이 들어가 있습니다.
이 pk 값으로 위에서 언급한 snippet, contentDetails, statistics를 이용하여 데이터를 추출하기 위함입니다.

유튜브 재생목록 안에 영상들 데이터 가져오기
video_list 에 재생목록 안에 있는 영상들의 pk 값이 저장되었습니다.
이제 그 영상들의 pk 를 이용하여 데이터들을 가져오겠습니다.
def get_my_selected_youtube_playlists(self, playlist_id: str):
"""
:param playlist_id:
:return: playlist_items
플레이 리스트 안에 있는 유튜브 영상의 상세 정보 데이터를 return.
"""
stats_list = []
stats_dict = {}
video_list = self.get_videos_from_playlists_items(playlist_id=playlist_id)
for i in range(0, len(video_list), 50):
response = self.youtube.videos().list(
part="snippet,contentDetails,statistics",
id=video_list[i:i+50]
).execute()
for video in response['items']:
url_pk = video['id']
channel_id = video['snippet']['channelId']
title = video['snippet']['title']
description = video['snippet']['description']
thumbnails = video['snippet']['thumbnails']['high']['url']
view_count = video['statistics'].get('viewCount', 0)
like_count = video['statistics'].get('likeCount', 0)
published = video['snippet']['publishedAt']
play_time = video['contentDetails']['duration']
stats_dict = dict(
url_pk=url_pk, channel_id=channel_id, title=title, description=description, thumbnails=thumbnails,
view_count=view_count, like_count=like_count, published=published, play_time=play_time
)
stats_list.append(stats_dict)
return stats_list, video['snippet']['channelTitle']def make_videos_csv(stats_list: list, channel_name: str):
df = pd.DataFrame(stats_list)
df.to_csv(f"/Users/cslee/vscode/get-youtube-data/csv/{channel_name}_영상들.csv")
snippet, statistics, contentDetails 를 사용하여 필요한 데이터들을 가져왔습니다.
가져온 데이터를 csv 로 만들어야 하기 때문에 데이터들을 list(dict) 형태로 저장했습니다.
마지막으로 def make_videos_csv 로 csv 파일을 만들었습니다.
argparse
전 게시글에서는 argparse 를 이용하여 재생목록만 가져왔습니다.
하지만 기능이 추가적으로 개발되었기 때문에 '-n' argument 를 추가해주겠습니다.
parser = argparse.ArgumentParser(description="유튜브 채널 이름을 입력해 주세요. EX) 곽튜브, 빠니보틀")
parser.add_argument('-c', '--channel')
parser.add_argument('-n', '--number')
args = parser.parse_args()
youtube = YouTube()
"""
target 에는 재생목록 리스트가 들어있다.
target[int(args.number)]['id'] 재생목록 id 를 가져온다.
target[int(args.number)]['snippet']['title'] 제목을 가져온다. EX) 1-유라시아 여행
"""
if args.channel == '빠니보틀':
target = youtube.get_all_youtube_playlists(channel_id='UCNhofiqfw5nl-NeDJkXtPvw')
make_playlist_csv(target, channel_name='빠니보틀')
if args.number:
youtube_video_list, channel_title = youtube.get_my_selected_youtube_playlists(
playlist_id=target[int(args.number)]['id'])
make_videos_csv(youtube_video_list, channel_title, target[int(args.number)]['snippet']['title'])
elif args.channel == '곽튜브':
target = youtube.get_all_youtube_playlists(channel_id='UClRNDVO8093rmRTtLe4GEPw')
make_playlist_csv(target, channel_name='곽튜브')
if args.number:
youtube_video_list, channel_title = youtube.get_my_selected_youtube_playlists(
playlist_id=target[int(args.number)]['id'])
make_videos_csv(youtube_video_list, channel_title, target[int(args.number)]['snippet']['title'])
else:
print("유튜브 채널 이름을 입력해 주세요.")poetry run python get_test_data.py -c 곽튜브 -n 0
이제 결과를 살펴보겠습니다!
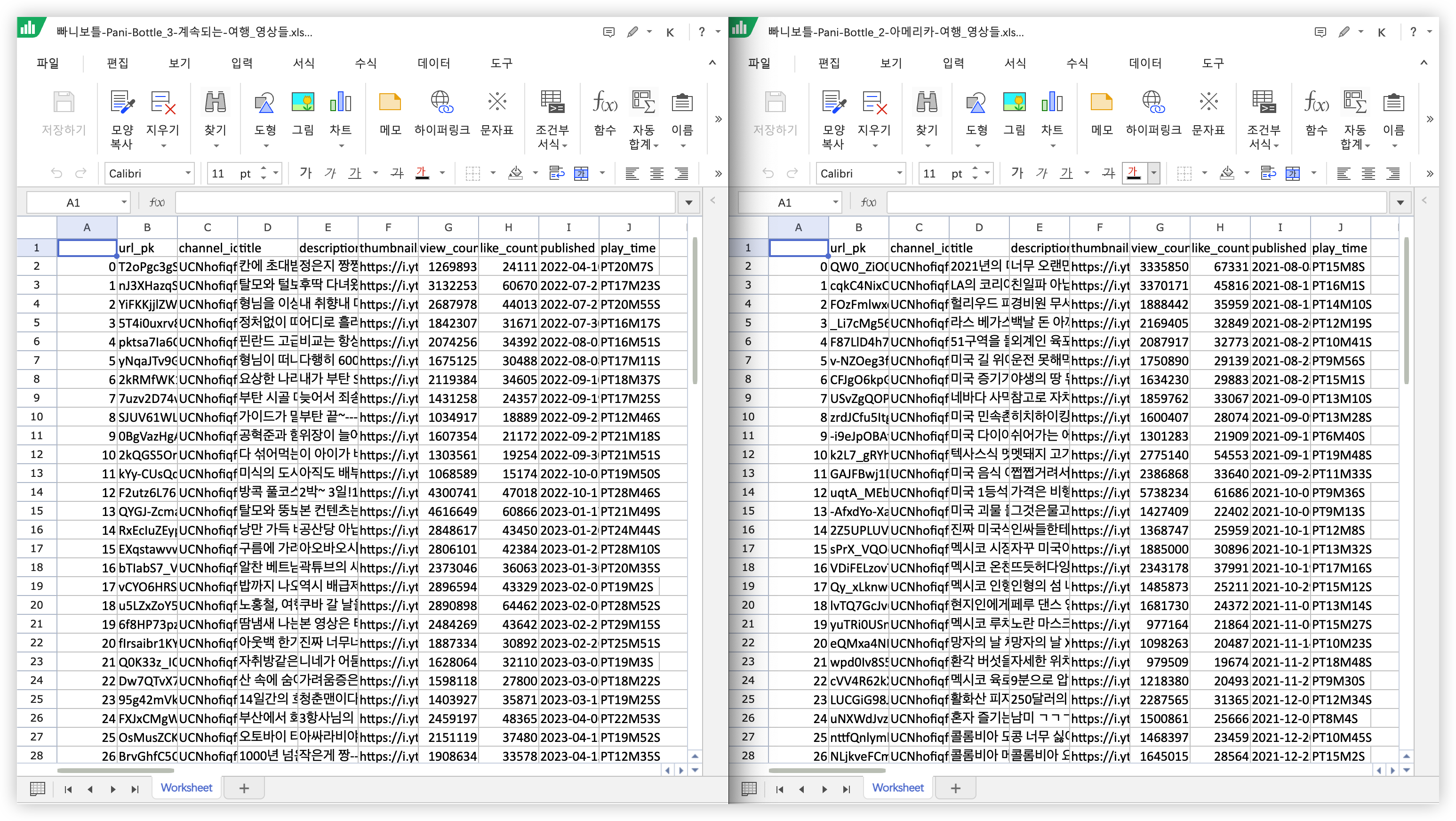
데이터도 잘 나오고 있습니다.
이런 주제로 프로그라피 8기 2팀으로 활동했고, 관련 게시글 링크 첨부하겠습니다!
momokji
👨🍳 재료들을 입력하여 레시피를 찾아보세요. momokji has 3 repositories available. Follow their code on GitHub.
github.com
https://github.com/2044smile/get-youtube-data
GitHub - 2044smile/get-youtube-data: Writing a blog with google api python client
Writing a blog with google api python client. Contribute to 2044smile/get-youtube-data development by creating an account on GitHub.
github.com
혹시 궁금한 점이나 잘못 된 부분이 있으면 댓글로 적어주시면 감사하겠습니다.
google-api-python-client, pandas, argparse 관련 게시글을 여기서 마무리 하겠습니다.
감사합니다!
'Language > Python' 카테고리의 다른 글
| [Python] Iterator, Generator 정리 (0) | 2025.12.26 |
|---|---|
| [FastAPI] 'Unknown Column' 에서 Alembic 사용법 (SQLAlchemy 스키마 동기화) (0) | 2025.06.15 |
| 'google-api-python-client'를 사용한 유튜브 데이터 가져오기 - pandas, argparse (2) (0) | 2023.08.29 |
| 'google-api-python-client'를 사용한 유튜브 데이터 가져오기 - Google Cloud 및 Python 설정 가이드 (1) (0) | 2023.08.24 |
| Python 나무위키 데이터 가져오기 (Pandas, datasets, parquet) (0) | 2023.06.23 |

댓글