
CUDA(Compute Unified Device Architecture)
- GPU의 수천 개 코어를 동시에 사용할 수 있게 해주는 프로그래밍 도구
- 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델로 GPU, Graphics Processing Unit을 활용해 일반적인 병렬 연산을 수행할 수 있게 해준다.
- PyTorch, TensorFlow 같은 프레임워크도 내부적으로 CUDA를 사용해 연산을 처리합니다.
- PyTorch -> CUDA -> GPU
개념
- 병렬 컴퓨팅 플랫폼으로 GPU에서 실행되는 코드를 작성할 수 있는 API를 제공한다.
- 개발자가 GPU의 연산 자원을 이용해 수천 개의 Thread를 병렬로 실행할 수 있게 하며, 이를 통해 대규모 데이터 처리 작업을 빠르게 수행할 수 있다.
구성 요소
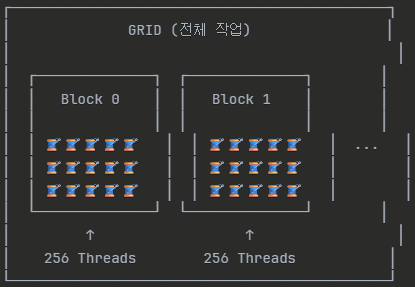
- Thread와 Block
- 병렬 처리를 수행하는 기본 단위
- Thread들은 Block이라는 그룹으로 묶인다.
- Block내의 Thread는 같은 메모리 공간을 공유할 수 있어 협력하여 연산을 수행할 수 있다.
- Grid
- Block들은 Grid라는 상위 개념으로 묶인다.
- Thread < Block < Grid의 계층 구조를 통해 GPU에서 병렬 처리를 조직화한다.
- CUDA Kernel
- 커널 함수는 한 번 실행될 때 수천 개의 Thread를 동시에 실행할 수 있습니다.
- CUDA에서 GPU에서 실행되는 함수를 커널(Kernel) 이라고 하며, __global__ 키워드를 사용해 정의한다.
- __global__ 함수는 호스트에서 호출되고, 디바이스에서 실행된다.
- __global__ 키워드는 이 함수가 GPU에서 실행될 커널임을 의미합니다.
- GPU에서 반환값을 직접 받지 않고, 결과는 GPU 메모리(예: cudaMalloc())에 저장된다.
- 커널 함수는 호스트(CPU) 측에서 호출되지만, 실제 연산은 디바이스(GPU) 에서 병렬로 수행된다.
- Memory Model
- CUDA의 메모리 모델은 크게 호스트(CPU) 메모리와 디바이스(GPU)메모리로 나뉜다.
- CUDA 프로그램에서 데이터를 처리하려면 호스트 메모리의 데이터를 디바이스 메모리로 복사하고, 연산한 후 다시 결과를 호스트 메모리로 복사해야 한다.
- Thread 구성
- 하나의 그리드(grid) 안에는 여러 개의 블록(block)이 있다.
- 각 블록은 여러 개의 Thread로 구성됨
- 병렬 연산의 단위는 바로 이 Thread
메모리 공간
CUDA에는 다양한 메모리 공간이 존재하며, 그에 따라 성능이 달라진다.
자주 사용하는 데이터는 공유 메모리에 저장하면 속도가 향상됩니다.
스레드 간 동기화를 통해 연산 충돌을 방지합니다.
- 전역 메모리(Global Memory): 모든 Thread가 접근할 수 있는 메모리 공간, 접근 속도가 느리지만 용량이 크다.
- 공유 메모리(Shared Memory): 동일한 블록 내의 Thread들끼리 공유할 수 있는 메모리 공간, 접근 속도가 빠르다.
- 레지스터(Register): 개별 Thread 전용의 고속 메모리 공간
- 상수 메모리(Constant Memory): 변하지 않는 데이터를 저장할 때 유용
병렬 프로그래밍 모델
- CUDA의 병렬 프로그래밍 모델은 SIMT Single Instruction, Multiple Threads 구조를 따른다.
- 이는 여러 Thread가 동일한 명령을 실행하되, 각 Thread는 서로 다른 데이터를 처리하는 방식
- 각 스레드는 고유한 인덱스를 가지며 이를 이용해 데이터의 특정 부분을 병렬로 처리할 수 있다
워프(warp)와 분기
- CUDA의 Thread들은 32개식 워프(warp)라는 단위로 실행된다.
- 즉, 32개의 Thread가 동시에 같은 명령을 실행하게 되는데 이 워프 내에서 서로 다른 조건문에 따라 명령이 갈라지면 성능이 저하될 수 있다. 이를 워프 warp divergence라고 하며 최대한 피하는 것이 성능 초적화에 중요하다.
성능 최적화
메모리 액세스 패턴
- GPU의 전역 메모리는 느리기 대문에 메모리 공동화(coalesced)를 통해 여러 Thread가 연속적인 메모리 주소에 접근하도록 하여 메모리 접근 효율을 높여야 한다.
공유 메모리 사용
- 공유 메모리는 전역 메모리보다 훨씬 빠르기 때문에, 가능하다면 데이터의 중간 결과를 공유 메모리에 저장하여 연산을 최적화할 수 있다.
적절한 블록 및 Thread 크기 설정
- 블록과 스레드의 개수를 적절히 조정하여 GPU 자원을 효율적으로 사용해야 한다.
- 블록의 크기가 너무 작거나 크면 성능이 저하될 수 있다.
- 일반적으로 32의 배수로 설정하는 것이 좋다.
전체 흐름
- CPU (Python/C++)
- 동영상 로드
- 전처리 설정
- Deep Stream SDK
- 무엇을 처리할지 결정
- CUDA
- 어떻게 GPU를 사용할지 제공
- GPU 병렬 처리
- 실제로 병렬 처리 수행
Reference
CUDA 개요
CUDA, Compute Unified Device Architecture 는 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델로, GPU, Graphics Processing Unit 을 활용해 일반적인 병렬 연산을 수행할 수 있게 해준다.1. CUDA 의 개념병렬 컴퓨팅 플랫폼
teach-meaning.tistory.com
https://digitalbourgeois.tistory.com/802
🚀 CUDA 프로그래밍 입문: Python 개발자를 위한 GPU 병렬 처리 가이드
Python 개발자를 위한 CUDA 프로그래밍 가이드딥러닝과 데이터 과학이 발전하면서 GPU를 활용한 연산이 필수적인 요소가 되었습니다. 특히, 병렬 연산이 중요한 작업에서는 CPU보다 GPU가 훨씬 강력
digitalbourgeois.tistory.com
'AI > Vision AI' 카테고리의 다른 글
| FPS(Frame Per Second)란 (0) | 2026.04.05 |
|---|---|
| DeepStream란? with Gstreamer (0) | 2025.10.20 |
| CLTR 군중 현지화를 위한 종단 간 변환기 모델 - 개념 (2) | 2025.05.23 |

댓글