
목차
- 들어가기 전에
- Argo Workflow란 무엇인가?
- Kubernetes란
- Installation
- minikube
- kubectl
- Argo Workflow
- 실습
- hello-world
- Dag & Step
들어가기 전에
Python&Django 주니어 개발자인 글쓴이가 구축해본 인프라 경험이라곤 AWS 사용 경험과 CI를 구축해본 경험 밖에 없는 상태에서 회사에서 새로운 프로젝트를 맡으면서 인프라 서브를 담당하게 되었고, Docker의 깊은 이해도 없는 상태에서 Kubernetes, Helm, Argo Workflow를 사용해야 되는 상황이 닥쳤고, 오늘은 그 중에서 Argo Workflow와 minikube를 사용한 간단한 실습을 진행하고 Argo Workflow에 대해 알아보도록 하겠습니다.
본격적으로 글을 시작하기 전에 Docker와 Kubernetes의 이해가 없으신 분들은 본 글을 읽기에 어려움이 있을 수 있습니다.
Docker에 대해 자세히 알아보고 싶다면 subicura님 블로그(링크)를 참고해주시고, Kubernetes에 대한 간단한 실습(링크)과 개념을 이해하고 싶다면 이 역시 subicura님의 블로그를 추천드립니다. 추가적으로 간단하게 읽으시는 분들을 위해 아래에 kubernetes와 minikube에 대한 설명을 해두었습니다.
Argo Workflow란 무엇인가?
Argo Workflow는 Kubernetes에서 병렬 작업을 조정하기 위한 오픈 소스 컨테이너 기반 워크플로우 엔진입니다.
Workflows는 Kubernetes CRD(CustomResourceDefinition)로 구현 됩니다.
공식문서에 나와있는 설명입니다, 하지만 kubernetes와 컨테이너에 대한 지식이 없다면 이것만 보고 이해하기는 쉽지 않습니다.
Argo Workflow에 대해 알아보기 전에 Workflow란 무엇을 말하는 걸까요? 말 그대로 '작업 흐름'을 의미합니다.
그렇다면 개발하면서 Workflow를 만들어서 사용해야 될 일이 뭐가 있을까요? Argo Workflow 공식문서에서는 기계 학습 또는 데이터 처리를 위한 컴퓨팅 집약적인 작업을 단시간에 쉽게 실행 할 수 있다고 합니다.
예를 들어 사진분석(A)와 결과도출(B) 라는 것이 컨테이너로 모듈화되어 있다고 가정하겠습니다.
사진분석(A)가 끝나면 사진분석 결과가 나오고, 결과도출(B)를 거쳐 사용자가 볼 수 있도록 데이터베이스에 저장합니다.
그렇다면 우리는 A -> B -> C 순서로 워크플로우를 만들어야 할 것 입니다.
사진분석(A), 결과도출(B)는 작업(Task)가 되고, 작업들을 순서대로 실행하기 위해서는 DAG를 사용하여 실행시킬 수 있습니다.이와 관련 된 실습은 아래서 진행해보도록 하겠습니다.
Kubernetes란
kubernetes는 서로 연결되어서 단일 유닛처럼 동작하는 고가용성의 컴퓨터 클러스터를 상호조정합니다. 애플리케이션 컨테이너를 클러스터에 분산시키고 스케줄링하는 일을 보다 효율적으로 자동화합니다.
마스터는 클러스터를 상호조정하고, 노드는 애플리케이션을 구동하는 작업자 입니다.

마스터는 클러스터 관리를 담당한다. 마스터는 애플리케이션을 스케줄링하거나, 애플리케이션의 항상성을 유지하거나, 애플리케이션을 스케일링하고, 새로운 변경사항을 순서대로 반영하는 일과 같은 클러스터 내 모든 활동을 조율한다.
노드는 쿠버네티스 클러스터 내 워커 머신으로써 동작하는 VM 또는 물리적인 컴퓨터다. 각 노드는 노드를 관리하고 쿠버네티스 마스터와 통신하는 Kubelet이라는 에이전트를 갖는다. 노드는 컨테이너 운영을 담당하는 containerd 또는 도커와 같은 툴도 갖는다. 운영 트래픽을 처리하는 쿠버네티스 클러스터는 최소 세 대의 노드를 가져야한다.
공식문서에서는 자세하게 스케쥴링과 항상성과 스케일링에 대해 설명하고있지만, 해당 글에서는 간단하게 알아보는 것이 목적이기 때문에 위의 개념에 대해 간단하게 풀어서 글로 써 보면 아래와 같습니다.
스케줄링 한다는 것은 컨테이너를 어느 노드에 구동시킬지를 스케줄 한다는 것을 말합니다. 예를들어 A,B,C 노드에 사용할 수 있는 자원이 아래와 같을 때 A(100%), B(78%), C(50%) 마스터는 A 노드에 사용할 수 있는 자원이 많기 때문에 컨테이너를 A에 위치시킬 겁니다.
항상성을 유지한다는 것을 이해하기 위해서는 파드(POD)라는 개념의 이해가 선행되어야 합니다. Kubernetes는 파드(POD) 안에 여러 개의 컨테이너를 구동시킬 수 있습니다. 즉 파드 안에 컨테이너들이 들어있는 것이고, 노드 안에는 여러 개의 파드들이 존재하게 되는 것 입니다.
위에서 말한 항상성을 유지한다는 것은 노드 안에 파드를 최소 몇 개를 유지해두겠다. 라는 것을 의미합니다.
스케일링한다는 것은 클러스터 안에 어느 노드에 파드의 사용량이 늘어날 때 Auto Scailing을 지원하여 사용자가 지정한 개 수 까지 사용량이 증가한다면 파드의 개수를 증가시켜줍니다.
노드는 마스터가 제공하는 Kubernetes API를 통해서 마스터와 통신한다. 사용자도 Kubernetes API를 직접 사용해서 클러스터와 상호작용할 수 있다.
Installation
Minikube
minikube를 설치하기전에 minikube가 무엇인지 간단하게 알아보도록 하겠습니다.
kubernetes 클러스터는 물리 및 가상 머신 모두에 설치될 수 있습니다. kubernetes 개발을 시작하려면 여러 선택사항이 있지만 본 글에서는 minikube를 사용하겠습니다. Minikube는 로컬 머신에 VM을 하나 만들고 하나의 노드로 구성된 간단한 클러스터를 배포하는 가벼운 kubernetes 구현체입니다.
진행에 앞서 Docker를 설치해주세요. 본 글에서는 Mac 환경에서 설치 가이드만 제공합니다.
다른 운영체제를 사용하시는 분은 링크를 눌러 설치하시기 바랍니다.
MacOS에서는 Homebrew를 통해 Minikube를 설치할 수 있습니다.
$ brew install minikube기본 명령어
# 버전확인
minikube version
# 가상머신 시작
minikube start --driver=hyperkit
# driver 에러가 발생한다면 virtual box를 사용
minikube start --driver=virtualbox
# 특정 k8s 버전 실행
minikube start --kubernetes-version=v1.20.0
# 상태확인
minikube status
# 정지
minikube stop
# 삭제
minikube delete
# ssh 접속
minikube ssh
# ip 확인
minikube ipKubectl
kubectl은 Kubernetes CLI 도구입니다. Kubernetes에 명령어를 전달하는 가장 흔한 방법입니다.
kubernetes API를 사용하면 쿠버네티스 API 오브젝트(파드(Pod), 네임스페이스(Namespace), 컨피그맵(ConfigMap) 그리고 이벤트(Event))를 질의하고 조작할 수 있습니다.
MacOS 외 다른 운영체제를 사용하시는 분은 링크를 눌러 설치하시기 바랍니다.
brew install kubectlOh My Zsh Shell을 사용하시는 분은 .zshrc 파일에 아래와 같이 설정해주면 kubectl 사용 시에 Tab키로 자동완성 시킬 수 있습니다.
# .zshrc
# Kubernetes
alias k='kubectl'
source <(kubectl completion zsh)
alias kgp='k get po'minikube & kubectl이 모두 설치되었다면 이제 minikube를 실행시키고, kubernetes 환경을 kubectl 명령어로 살펴볼 수 있습니다.

Argo Workflow 설치
# argo 네임스페이스 생성 ns(namespace)
kubectl create ns argo
# 네임스페이스 변경
kubectl config set-context --current --namespace argo
# argo namespace에 argo 구동에 필요한 resource 설치
kubectl apply -n argo -f https://raw.githubusercontent.com/argoproj/argo/stable/manifests/namespace-install.yaml
위 사진을 보시면 아래에 2개의 파드가 생성되었습니다.
생성 된 파드들 중 argo-server-xxxx 파드는 Argo Workflow Web UI 를 접속할 수 있는 파드입니다.
kubectl port-forward argo-server-xxxx 2746
또는
argo server명령어로 포트 포워딩하여 로컬에서 접속할 수 있습니다.
workflow-controller-xxxx 파드는 workflow들을 컨트롤 할 수 있는 파드입니다.
hello-world
docker/whalesay 이미지를 사용하여 컨테이너를 띄우고 hello world를 출력해보도록 하겠습니다.
그 전에 워크플로우를 실행하기 위해서는 권한(ServiceAccount, Role, RoleBinding) 이 있어야 합니다.
Argo가 artifact, outputs, secrets access 등과 같은 기능을 지원하려면 Kubernetes API를 사용하여 Kubernetes 리소스와 통신해야 합니다. Kubernetes API와 통신하기 위해 Argo는 ServiceAccount를 사용하여 Kubernetes API에 자신을 인증합니다.
워크플로우를 제출할 때 사용 할 ServiceAccount를 지정합니다.
argo submit --serviceaccount default하지만 default는 기본적인 권한만 갖고 있기 때문에 관리자 권한을 부여해주도록 하겠습니다.
kubectl create rolebinding default-admin --clusterrole=admin --serviceaccount=argo:default -n argo위 설정을 하지 않으면 failed to save outputs: Failed to establish pod watch: timed out waiting for the condition 와 같은 오류가 발생합니다.
# example-hello.yaml
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world- # generateName을 사용하면 hello-world-xxxx-xxxx
namespace: argo
spec:
entrypoint: whalesay # 시작 할 templates을 지정합니다.
templates:
- name: whalesay
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["hello world"]example-hello.yaml 안에 정의한 내용을 설명해보면
- apiVersion: 말 그대로 apiVersion 입니다. 보통 v1을 사용합니다.
- kind: kubernetes resource 종류를 정의합니다. ex) Pod, Service, Deployment . . .
- spec: resource 의 상세 스팩을 정의합니다.
- entrypoint: 워크플로우를 실행 할 때 처음으로 실행할 template을 지정합니다.
- container: 파드 안에 컨테이너를 지정합니다.
아래 명령어로 만든 example-hello.yaml 파일을 submit 하겠습니다.
argo submit example-hello.yaml
workflow가 돌아가고 있는지 확인하는 방법은 여러가지 방법이 있습니다.
# 파드가 생성되어 돌아가고 있는지 확인
kubectl get pod
# workflow status와 duration을 확인
argo list
# Web UI 접속하여 확인
argo server 또는 kubectl port-forward argo-server-xxxx-xxxx 2746
localhost:2746으로 접속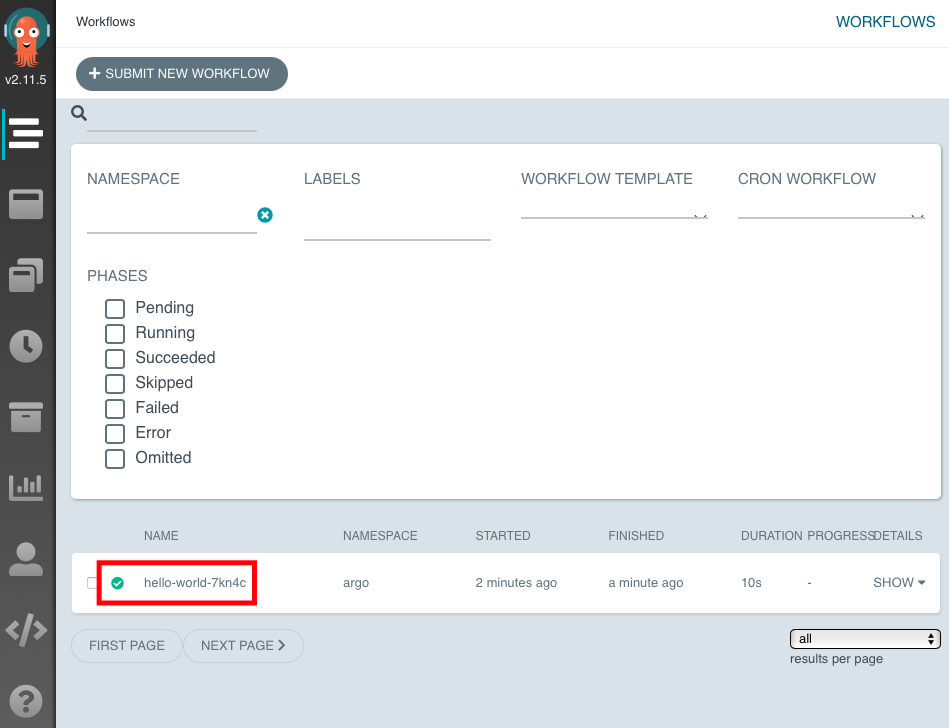
Argo Web 에서는 많은 것들을 확인할 수 있습니다.
만들어둔 template들을 Web에서 submit 할 수도 있고, Cron Workflow를 설정할 수도 있습니다.

위 사진에서 LOGS를 클릭하게 되면 yaml 파일을 정의할 때 args로 넣은 hello world가 출력되는 것을 확인할 수 있습니다.

Dag & Step
Dag와 Step을 이용하여 다단계 Workflow를 만들 수 있습니다.
둘 이상의 템플릿을 정의할 때 병렬로 동시에 처리할지 아니면 한 개의 Workflow가 완료되면 나머지 Workflow를 처리할지(종속성)에 대한 템플릿을 정의하는 방법들 입니다. 사실 Dag와 Step의 차이는 큰 차이가 없습니다. 아래 예시를 따라 만들어보겠습니다.
Step
# example-step.yaml
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: steps-
spec:
entrypoint: hello-hello-hello
# This spec contains two templates: hello-hello-hello and whalesay
templates:
- name: hello-hello-hello
# Instead of just running a container
# This template has a sequence of steps
steps:
- - name: hello1 # hello1 is run before the following steps
template: whalesay
arguments:
parameters:
- name: message
value: "hello1"
- - name: hello2a # 이전 스탭이 끝나면 실행됩니다.
template: whalesay
arguments:
parameters:
- name: message
value: "hello2a"
- name: hello2b # 이전 스탭과 병렬로 진행됩니다.
template: whalesay
arguments:
parameters:
- name: message
value: "hello2b"
# This is the same template as from the previous example
- name: whalesay
inputs:
parameters:
- name: message
container:
image: docker/whalesay
command: [cowsay]
args: ["{{inputs.parameters.message}}"]templates 안에 hello-hello-hello와 whaleasy 템플릿이 정의되어 있습니다.
hello-hello-hello 템플릿은 Workflow을 동작하기 위해 만들어둔 템플릿이고, steps안에 whalesay 템플릿을 호출하여 arguments로 값을 넣어주면 앞서 보았던 hello world 처럼 결과가 나오게 됩니다.
argo submit 명령어로 workflow를 트리거 해보겠습니다.
argo submit example-step.yaml
hello2a, hello2b가 동시에(병렬) 돈 이유는 hello2b가 -(single dash)로 되어있어 이전 step과 병렬로 돌기 때문입니다.
Dag
앞서 말했듯이 step과 dag의 차이는 거의 없다고 봐도 상관없습니다.
한 가지 차이점이라면 dependencies로 종속성을 설정할 수 있고, step의 경우에도 간단한 워크플로우의 single dash를 사용하여 경우 설정할 수 있지만 복잡한 워크플로우라면 Dag를 사용하는 것이 현명해보입니다.
# example-dag.yaml
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: steps-
spec:
entrypoint: hello-hello-hello
templates:
- name: hello-hello-hello
dag:
tasks:
- name: A
template: whalesay
arguments:
parameters:
- name: message
value: "A"
- name: B
dependencies: [A] # A가 완료되면 동작
template: whalesay
arguments:
parameters:
- name: message
value: "B"
- name: C
dependencies: [A] # A가 완료되면 동작
template: whalesay
arguments:
parameters:
- name: message
value: "C"
- name: D
dependencies: [B, C] # B, C가 완료되면 D가 동작하도록
template: whalesay
arguments:
parameters:
- name: message
value: "D"
- name: whalesay
inputs:
parameters:
- name: message
container:
image: docker/whalesay
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
이렇게해서 간단하게 kubernetes환경을 minikube 구축해보고, Argo Workflow를 설치하여 워크플로우를 만들어 동작시켜보았습니다.
원래는 '주니어 개발자의 Argo Workflow 사용기'라는 제목으로 경험했던 내용을 작성해보려 하였으나, Argo Workflow의 개념에 대해 얘기해고자하니 실습 할 수 있는 환경과 예시가 있다면 좋겠다는 생각이 들어 1편은 Argo Workflow에 대해 실습해보고 kubernetes에 대해서도 간단히 알아볼 수 있는 글을 작성해보았습니다.
2편에서는 Argo Workflow를 사용하면서 경험했던 내용들을 위주로 작성해보겠습니다.
감사합니다.
'Devops' 카테고리의 다른 글
| Jenkins X v3 란 무엇인가? - 1 (0) | 2021.02.21 |
|---|---|
| 주니어 개발자의 Argo Workflow, Events 사용기 - 2 (2) | 2021.02.07 |
| [AWS STS] error: You must be logged in to the server (Unauthorized) 삽질일기 (0) | 2020.10.21 |
| Docker Ubuntu18.04 java (jdk, jre)설치 및 오류해결 (0) | 2020.08.13 |
| Argo Workflow failed to save outputs: Failed to establish pod watch: unknown (get pods) Error (0) | 2020.07.23 |

댓글